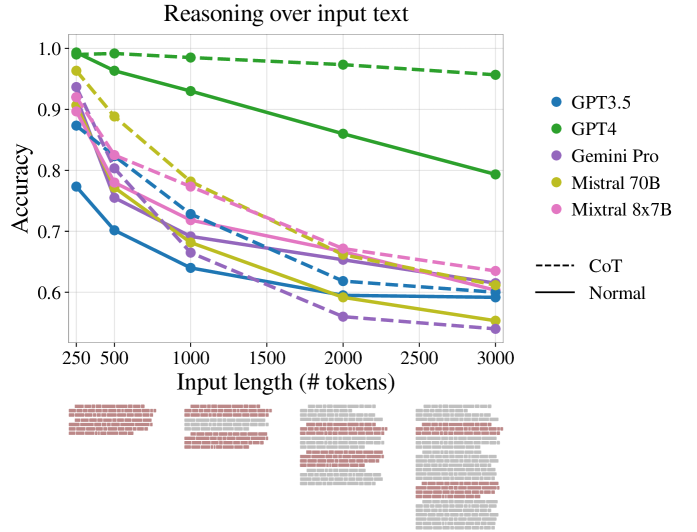
Mind your prompt lengths. A new paper explores the relationship between input length and performance of large language models. The study found that performance can begin to significantly degrade with as few as 3000 tokens. In this case, the tokens we are talking about are extraneous to the input needed to answer the question, but it brings to light the importance of managing your context.
This has broad applicability in RAG applications where different information retrieval (IR) technologies are used to return relevant content that the LLM uses to answer your question. Choosing IR methods that maximize signal to noise can be critical for the performance of your LLM. To say nothing of the cost reduction of using fewer tokens if you are using an API.
The second interesting observation is that Chain of Though (CoT) reasoning did not have a significant impact on this degradation EXCEPT for GPT-4. What this seems to indicate is for non GPT-4 models, focus on distilling inputs, and with GPT-4 consider leveraging CoT especially with longer input lengths.
The researchers have not yet explored Gemini with 1.5b token context length, so that remains to be seen.
References: